
Scraping data from bot-protected websites using proxy api
The grey-ish way of winning the never ending cat and mouse game for the right purpose.


Web scraping is a challenging. It's potentially legally binding grey-ish area of technology, except everyone is doing it. Everyone wants your data and you want everyone's data.
One of my clients wanted to extract data from a site protected by cloudflare and another one protected by datadome. The main goal of the project was to create a product comparison website.
We need the product data before being able to compare them, right? But both sites were heavily protected from bot attacks. Even just opening the website directly would show a bad looking forbidden screen.
The targets
For ease of explanation I will go through few websites. The test will be to just being able to load the page, if it can be loaded, most probably it can be scrapped. Though we do not want to scrape data from pages which does not want us to scrape their data, except sometimes the website does not even load for a human like me if I were to browse from a different part of the world and extract the data manually.
Website 1: Sephora.com
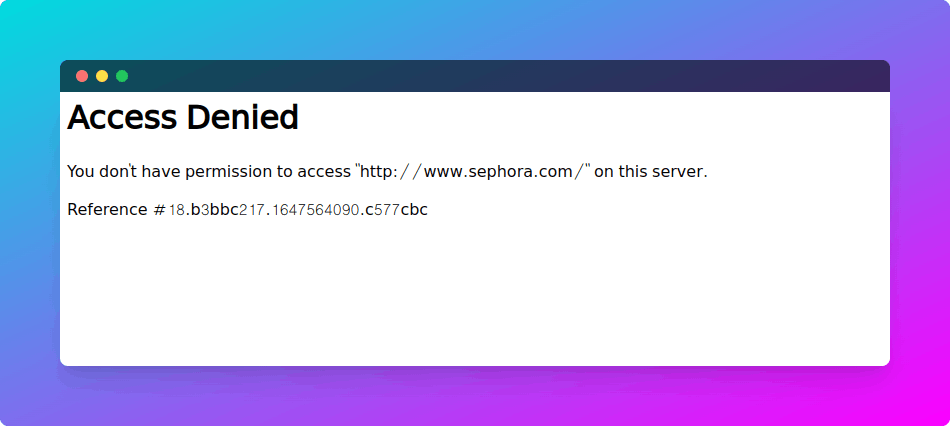
This is a popular website with a strong bot protection. However their data is not absolutely private. It's actually accessible directly using different domains listed in their SEPHORA INTERNATIONAL page.
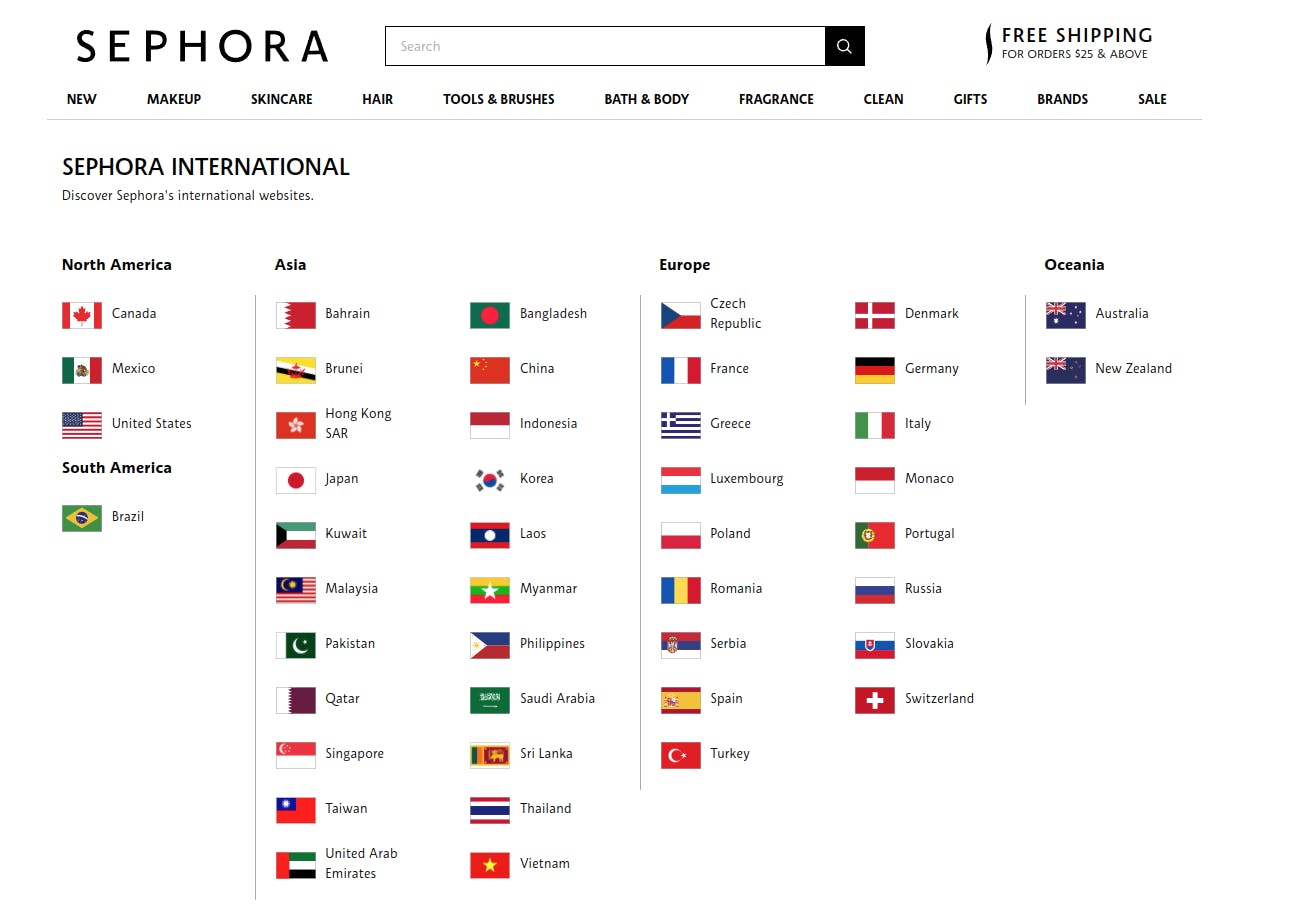
Our goal for this website is to load their main USA based website at sephora.com rather than international ones.
Website 2: Booking.com
This is a popular hotel to find deals about hotel, flights, rentals etc. To be able to check difference for different hotel price between this website and few others like kayak, expedia, we built a bot, which ultimately failed to load the website after a few tries.
Grey-ish you say?
Yes, this is a grey-ish area. If I were the admin of the sephora or booking, I would not probably want someone to extract my data and put a very strong bot protection. However I have affiliates whom I pay to refer to my website and expect them to take list hundreds of products from my website, without giving them direct access to the website itself?
If I am an affiliate, I need to collect as much as data possible from the sites I have permission to collect data from, so I can build projects around it, maybe a comparison website, and drive traffic to them directly.
- If I were not given permission to collect data from the website as an affiliate, and if the bot would actually do more harm than good, then it's a black area.
- If I were able to load the page properly and copy paste some of the product data manually, then share to my website as an affiliate, it's a white area.
- Now, since I am allowed as an affiliate, but still cannot load the website, so I have to extract data somehow else, which is the same data they are giving to public eyes like google, it's a grey-ish area.
Bypassing the protection
I could just load the page with a vpn and collect my desired data. But that sounds no fun when there could be hundreds of thousands of products, or some of the products are updated frequently. Who got time to visit the product pages every day to check for changes? No one!
Another neat solution is to throw bunch of premium residential proxies with a puppeteer/playwright instance. It has it's own pain points, but being able to fire up a bot that notifies you about a price change, so you can grab the deal or promote it on social media sites sounds really fun and helpful.
However if I do not want to handle scaling related issues, I could just use a proxy api provider. There are tons of them like ScraperAPI, ScrapingBee, ScrapeStack, ScrapeUp, ProxyCrawl and more.
Not all of the providers were successful to load the sites properly. Here is a minimal comparison of which provider were able to load which website.
| Site/Service | ScraperAPI | ScrapingBee | ScrapeStack | ProxyCrawl |
| Example.com | ✅ | ✅ | ✅ | ✅ |
| Datadome Blog | ✅ | ✅ | ❌ | ✅ |
| Sephora.com | ✅ | ✅ | ❌ | ✅ |
| Booking.com | ✅ | ✅ | ✅ | ✅ |
| FastPeopleSearch.com | ✅ | ❌ | ❌ | ❌ |
Ironically datadome is a very expensive bot protection service and talks about scraperapi and anti-bot protection case-studies. Being able to load their blog with the bot defeats the very purpose they were created.
Anyway, out of all of these bot protection service, only ScraperAPI were able to load the websites almost every time without any massive pain. I just needed to ensure the javascript rendering was enabled when loading the page. If it failed, I would enable premium residential proxies which would be even harder to detect.
To make it work, we need to have a subscription of the proxy api services. Almost every service provides free credits to get started. ScraperAPI provides with 1k free credits with all of the premium features enabled.
Let's see some small code to see how it is.
const axios = require('axios').default;
async function scrape(){
return await axios
.get('http://api.scraperapi.com', {
params: {
api_key: "API_KEY",
url: "https://sephora.com",
render: true
}});
}
scrape();
It will open the website using proxy, get the html data and share it to you for further processing on your end. If there is a captcha, it will try to solve it for you. It may take 5-10-30 seconds to deliver you the content because behind the back, it's creating a new chrome window for you, using the proxies to get data.
ScraperAPI also has an proxy mode, where you can use them as proxies, but I do not suggest that. Loading sephora loads about thousands of images/assets, and using scraperapi as direct proxy would cost me 1-2k credits each page compared to 1-5 credits normally. It's crazy.
Wrap up
This is not a marketing post about scraping proxies api, more will be discussed soon about how to build your own proxy service to take care of such websites with heavy bot-protection for the people who need the data as a real human.
Until then, good luck and have fun scraping data from bot protected websites with proxy api services.